The Problem: Modern Speed Meets Legacy Limits
Modern systems move fast. Legacy APIs don’t. When high-throughput workloads hit low-throughput endpoints, you either start getting 429s—or worse, 500s and ETIMEDOUT errors that leave you guessing whether the work actually completed.
Some targets offer async queues. Most don’t. That leaves you building your own flow control—polling workers, retry logic, backoff strategies, and compute you’d rather not burn. You still need to preserve state across calls and handle all the ugly failure modes.
The Solution: Lean on AWS Primitives
With AWS, the more you can do using primitives, the simpler and more reliable your architecture becomes. If you’re reaching for distributed locks or building custom schedulers, stop and ask: “Is there a native way?”
We’ve adopted a clean pattern using Step Functions, SQS, and Lambda concurrency limits to solve for rate limits, priority, and async state—all without unnecessary complexity.
The Pattern in 3 Steps
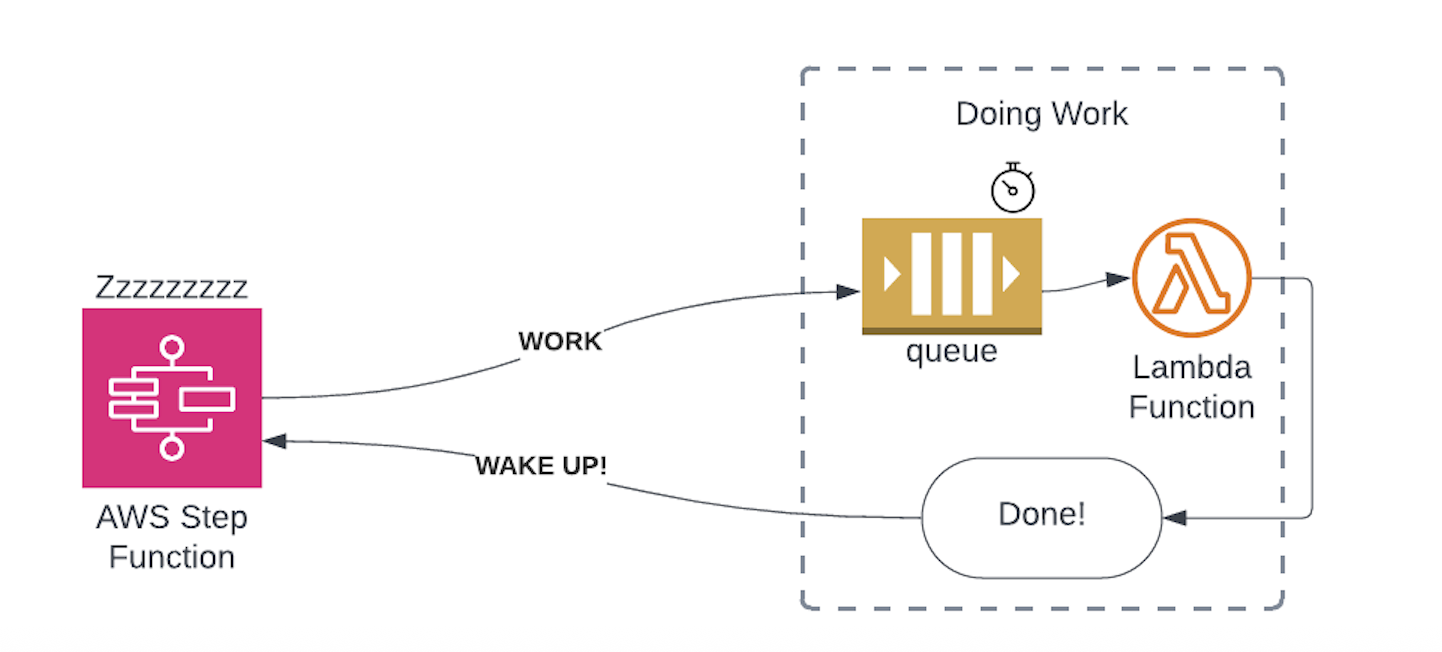
1. Use Task Tokens to Pause Workflow Execution
Step Functions can pause execution and wait for a worker to call back using a task token. No compute consumed. State preserved for up to one year.
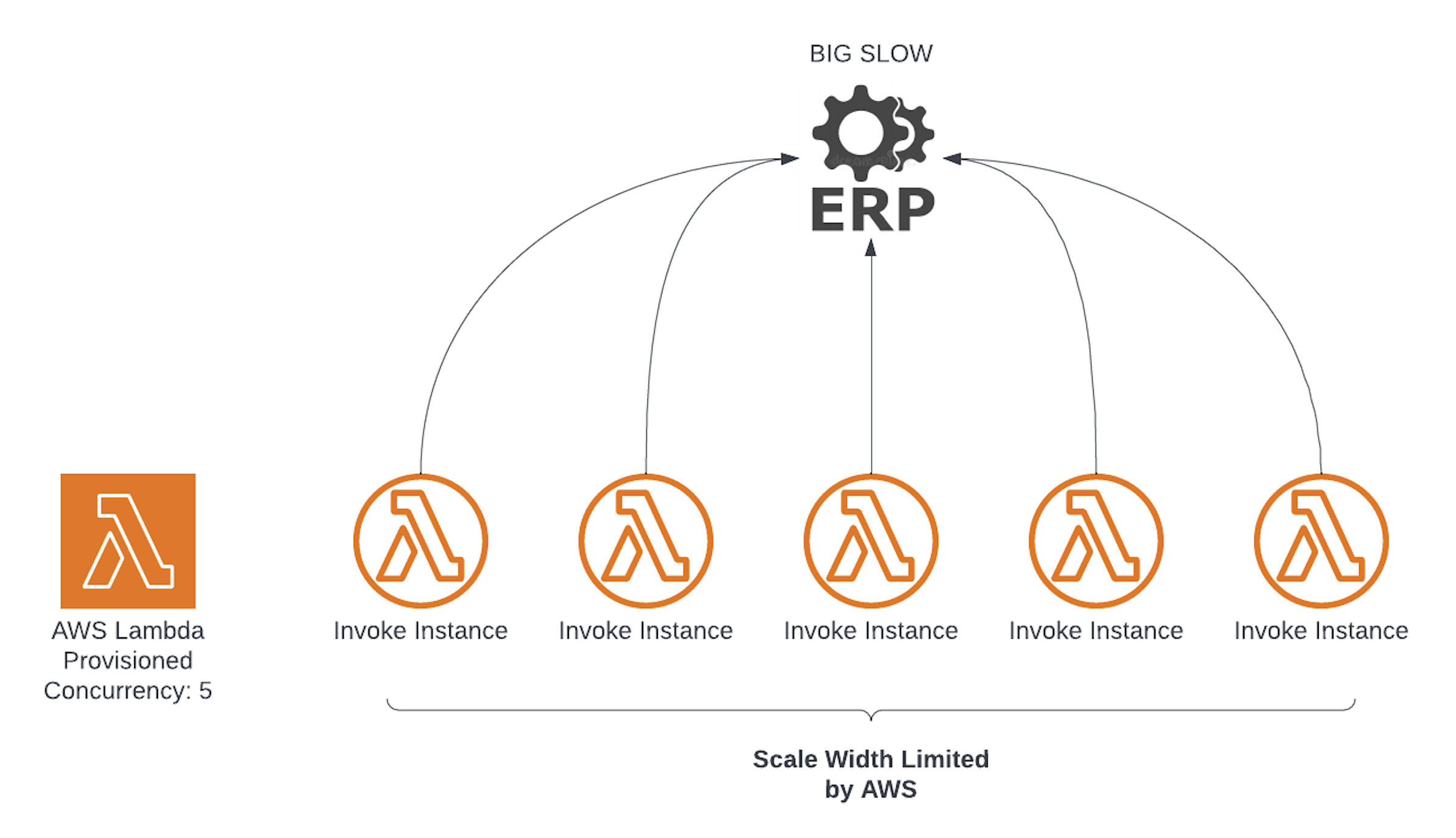
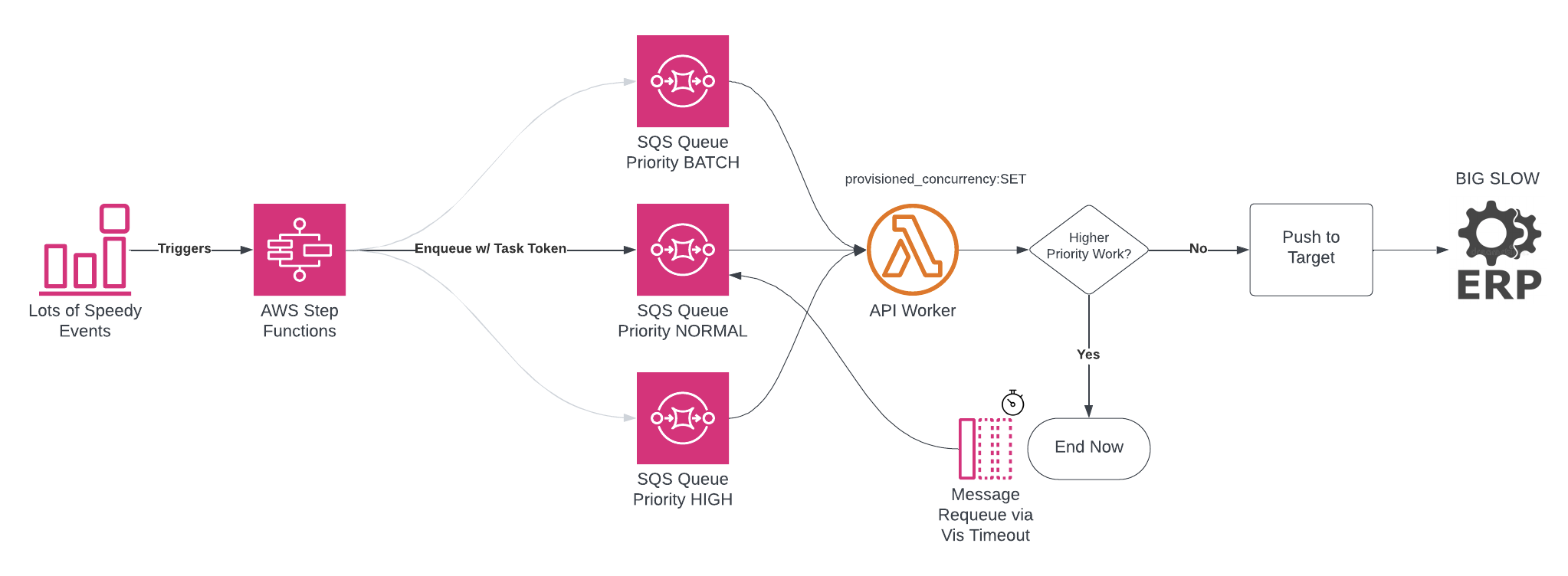
2. Queue Work, Let Lambda Concurrency Throttle It
The Step Function drops a message on a queue. A single Lambda (with provisioned concurrency set to the rate limit) pulls from the queue. No polling logic, no distributed locks. AWS handles the rest.
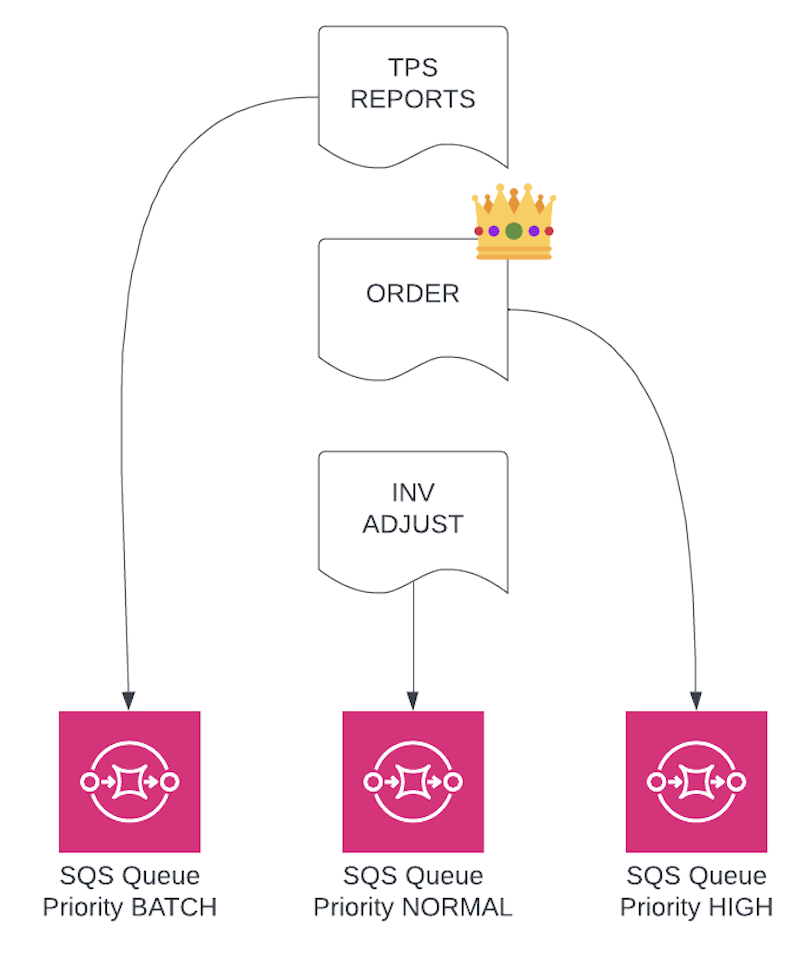
3. Use Multiple Queues for Priority
We define three: HIGH, NORMAL, and BATCH. Priority logic happens inside the Lambda.
Smart Priority Handling
The worker checks queues in priority order:
Worker: About to handle a NORMAL message. Let me check HIGH real quick…
HIGH Queue: Yep, got one.
Worker: Cool, I’ll let this NORMAL message time out and come back later.
That timeout-based deferral lets us handle higher-priority work immediately without losing lower-priority messages. If a message hits the max receive count, we just process it—no DLQ clogging.
Why It Works
We’re not inventing new systems—we’re composing native ones:
- Step Functions for async state and orchestration
- Task Tokens to pause flows cleanly
- SQS for buffering and retry
- Lambda Concurrency as a built-in rate limiter
- Multiple Queues + Visibility Timeout for simple priority scheduling
The result is composable, transparent, and easy to debug. No guesswork. No fragile custom logic.
Monitoring and Results
Every component emits metrics: queue depth and age by priority, execution time, failure counts. Since adopting this pattern, we’ve eliminated rate limit violations, reduced cost, and made critical operations consistently responsive.
Where Else It Fits
Anywhere you need orderly, rate-limited access to shared resources—APIs, databases, backend systems—this pattern holds up. It’s not just effective. It’s elegant.